As I’ve mentioned briefly in a previous post, I’ve been building out an AI Agent Team to help me with my personal development projects. I’ve named them ‘Team Mustang’—a nod to Fullmetal Alchemist. The current roster consists of Roy, Breda, and Hawkeye, who serve as the Planner, Generator, and Evaluator, respectively. Those of you who are keeping up with the latest trends will probably recognize this as the architecture mentioned in the Claude blog.
The prompts for each agent are relatively simple: links to shared documentation, a two-line identity statement, a five-line R&R (Roles & Responsibilities) description, and three lines of Discord channel rules. Even the shared documents—the CONSTITUTION and WORKFLOW—are modest, consisting of just 34 and 67 lines respectively. I’ve placed all three agents in a single Discord channel. Now, looking back, I realize Claude has a built-in Agent Team feature that probably would have worked, and honestly, I didn’t even know it existed when I started building this. But even knowing it now, considering the pros and cons of each approach, I think I’ll stick with my current setup for a while.
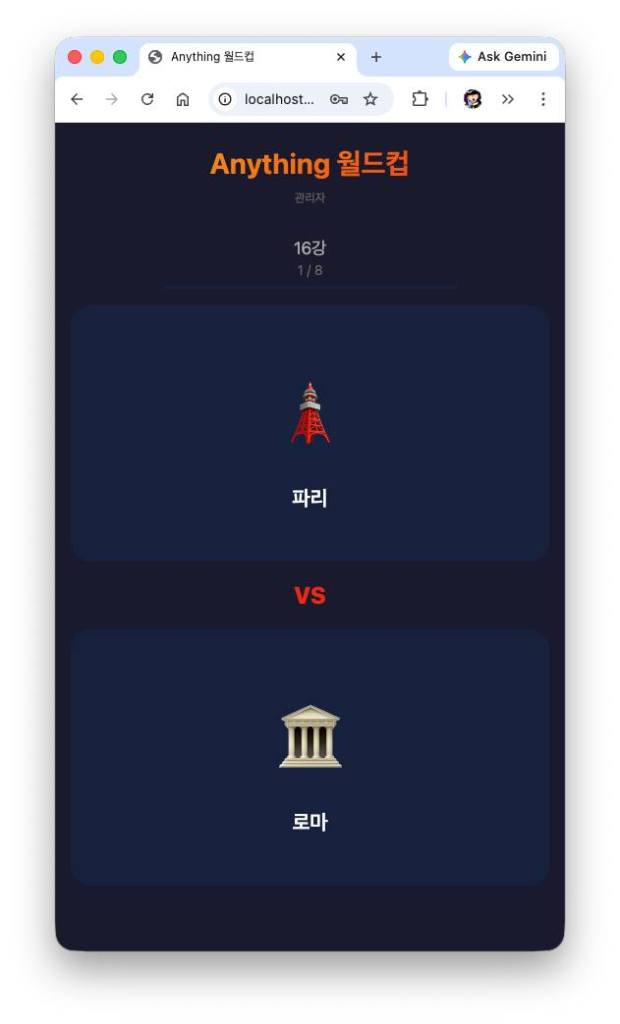
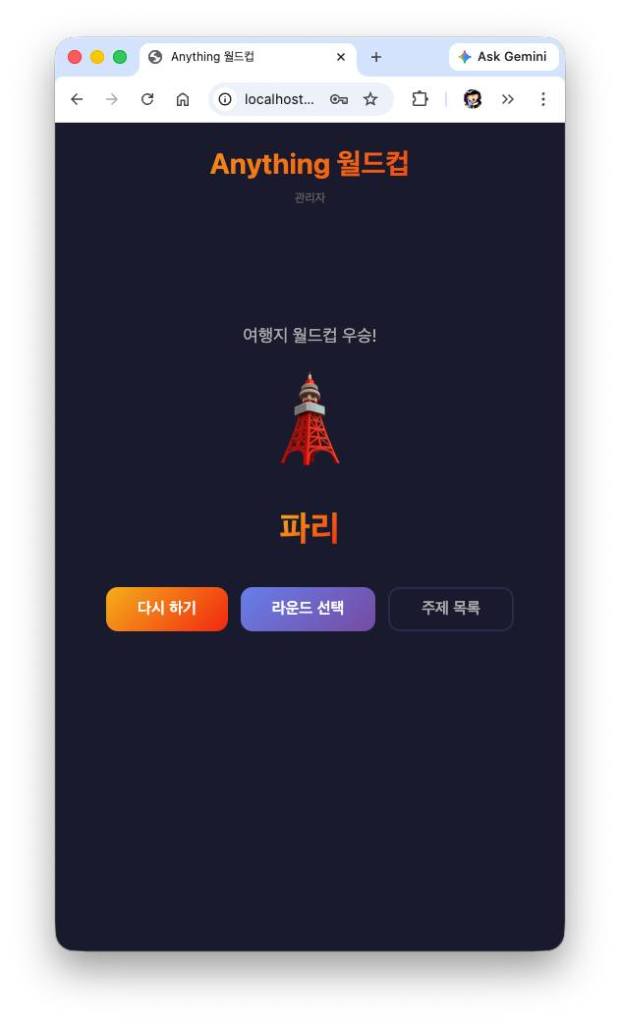
Once the team was assembled, the next step was to see if they actually worked. I picked a modest task to put them through their paces and decided to compare the results against a single Claude Code session. The project: “Anything Worldcup”—one of those classic internet time-killers where you pick a theme, list candidates, and run a tournament to decide the ultimate winner.
I sent the following prompt to both the team and the single session:
> “I want to build a simple website for a game called ‘XXX Worldcup.’ The user is presented with two items at a time and chooses a preference in a tournament format until a final winner is decided. Since ‘Anything’ is too vague to start with, feel free to pick a specific theme for the development process. No need to save the results; just a working demo is enough. Local execution is fine.”
The team finished in four minutes without any additional instructions. I noticed them exchanging opinions and refining the output among themselves. The single Claude Code session also handled it perfectly on its own in about two minutes. Both versions worked fine; the only real difference was the design. In my opinion, the single session’s design was slightly better, but since I hadn’t provided specific UI instructions, I ignored it and moved to the next prompt.
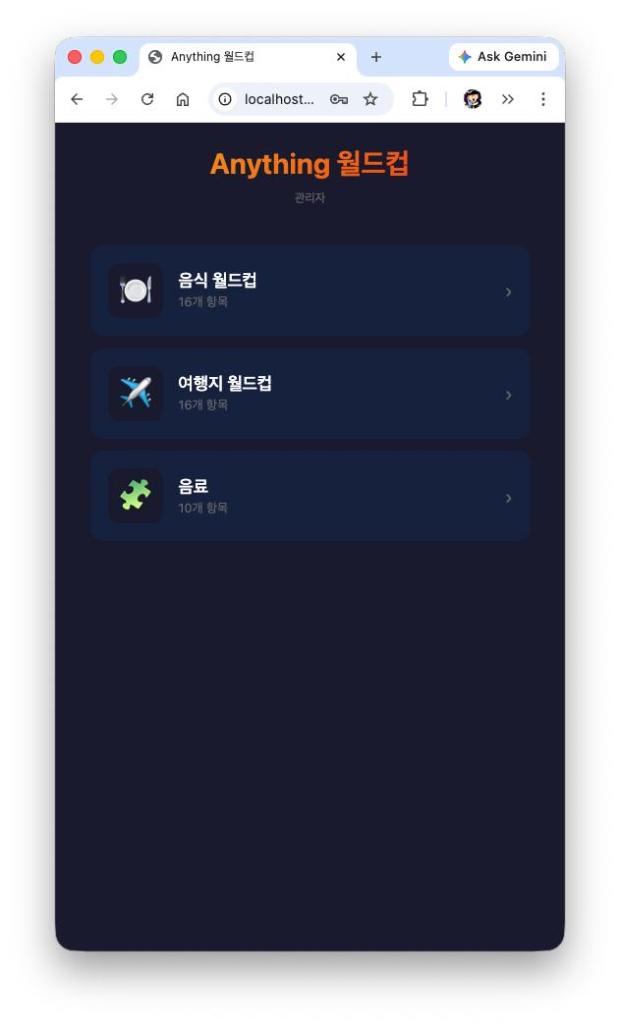
> “Since the project is called ‘Anything Worldcup,’ we need a way to handle different lists. Add a screen where the user can select a list, and once selected, the tournament starts. Also, please define an additional theme.”
Both finished smoothly. The single session was slightly faster again, but not significantly so. One notable difference: Team Mustang handled the commits automatically (which Claude Code didn’t), and Hawkeye pointed out a specific code quality issue:
> “In the show() function, the ternary operator has identical results for both cases (‘block’ : ‘block’), making the branch redundant. It doesn’t affect functionality, but it’s a good spot for cleanup.”
Roy asked me if I wanted it fixed, I said yes, and they handled the fix and the commit autonomously. Then, I pushed them further:
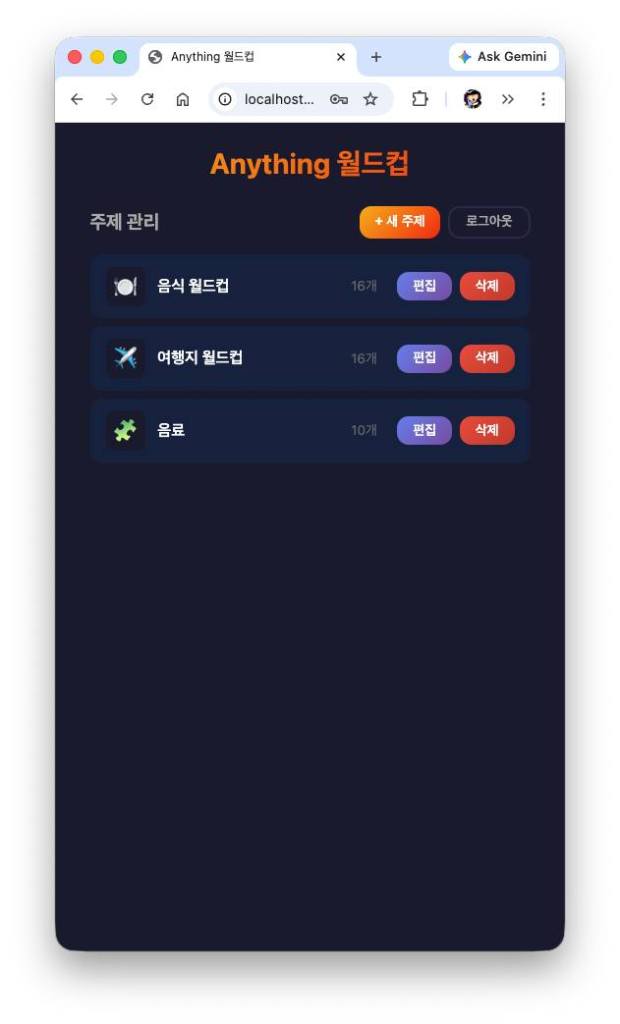
> “Update the site so users can add their own themes and input data. The theme and item CRUD should be fully functional. Since each item needs a name and an image, please implement image uploads.”
Both finished in about five minutes. Again, the team handled the commits, while the single session did not. The edit screen from the single session was more intuitive and better designed—likely because I hadn’t specified a UI framework, so it took more creative liberty. There was also a difference in storage: the single session used the browser’s localStorage, while the team initially just used in-memory storage, meaning everything vanished on a page reload. Furthermore, if the number of items wasn’t a power of two, the single session just discarded the remainder and proceeded, whereas Team Mustang’s version simply refused to start the game. In short, where the spec was vague, Team Mustang’s choices were consistently less refined.
However, there was one standout advantage: because Team Mustang has Hawkeye (the Evaluator), the process was filled with constant self-reflection.
> “Advisory: If a user tries to add an item before saving a new theme, an error message appears. Two possible directions: 1. Disable the ‘Add Item’ button until the theme is saved. 2. Keep the error message as is (it works fine). I suggest option 1.”
I agreed to option 1. During testing, I noticed the data still vanished on reload, so I asked them to fix that. The team then switched to localStorage.
After several more iterations of adding requirements, we ended up with a split frontend and backend, a simple admin page, and a structure where regular users only play the game while admins can edit themes and items. The backend used SQLite to manage the data. While both versions implemented the core features faithfully, my subjective feeling was that the single session’s version had better “unasked-for” detail. But the fact that the team could self-correct and actually function as a unit was a huge win.
To wrap things up, I asked Hawkeye to perform a self-diagnosis of the project workflow:
> “Alright, let’s stop here. Hawkeye, we’ve gone through 4-5 iterations. Can you summarize the overall workflow? Tell me what worked well and what was lacking.”
Here was Hawkeye’s summary:
What worked:
1. Role Separation: The cycle of Spec (Roy) → Pre-review (Hawkeye) → Implementation (Breda) → Evaluation (Hawkeye) ran autonomously without my intervention.
2. Pre-review Value: Issues like “per-round shuffle” and data array separation were caught before implementation, significantly reducing rework.
3. Blocking vs. Advisory: Even in iterations without “blocking” issues, the team actually implemented “advisory” feedback, creating a virtuous cycle of quality improvement.
What was lacking:
1. Cumulative Success Criteria: We defined new criteria each iteration, but there was no regression check to ensure old features still worked.
2. Advisory Tracking: Some advisory points (like an XSS issue) were left as “Should I fix this?” without a formal system to track whether they were eventually resolved.
3. Manual Evaluation Triggers: Evaluation only started when Roy specifically asked Hawkeye. An automated trigger based on Breda’s completion report would be more efficient.
4. Communication Mismatch: Advisory reports were supposed to go only to Roy, but in a single Discord channel, everyone saw everything.
Bottom line: The role separation and pre-review structure worked great. The next step is improving regression management and advisory tracking.
After reviewing Hawkeye’s feedback, I refined the roles and workflow, which naturally led to the introduction of SDD (Specification-Driven Development). The experience I posted about a few days ago with Team Mustang was actually based on this refined, SDD-enabled version.
I originally intended to end the post there, but I couldn’t shake the feeling that the “single session” version had won on a first-glance, subjective UI/UX level. I wondered what would happen if I used a more objective metric: code quality. So, I opened a third, independent Claude Code session and gave it this prompt:
> “These two projects, anything-worldcup-team-mustang and anything-worldcup-claude, were built from the same spec. Please analyze both, comparing their strengths and weaknesses. Focus specifically on current functionality, completeness, and future maintainability.”
The result was a detailed report. Here is the summarized version:
anything-worldcup-team-mustang (A)
– Strengths: High test coverage (23 pytest + 12 Playwright E2E) mapped to specs; Type-safe DB access via SQLAlchemy ORM; Robust JWT-based auth; Proper environment variable management via .env; Restricted CORS.
– Weaknesses: Heavy use of inline styles in JSX; No seed data (starts with an empty screen); No result storage (same as B).
anything-worldcup-claude (B)
– Strengths: Polished UI/UX (gradients, animations, progress bars, modal overlays); Defined design system in styles.css; Included seed.py for easy setup; Better game feel with a 500ms delay and visual feedback on selection.
– Weaknesses: Zero tests; In-memory token storage (sessions wipe on restart); Raw sqlite3 usage (higher SQL injection risk, manual migrations); Hardcoded admin credentials; No .env file.
Overall Evaluation:
– Backend Robustness: A (ORM, JWT, .env, Tests)
– Frontend UX: B (Animations, Responsive, Design System)
– QA/Testing: A (Overwhelming win: 35 tests vs 0)
– Production Readiness: A (Auth, Config, Tests)
Final Verdict:
A is rock-solid in the “invisible” areas (tests, ORM, auth, config), while B is polished in the “visible” areas (UI, style, initial experience). The ideal product would be A’s backend with B’s frontend.
In the end, the “team” produced a objectively more durable product. However, the fact that the single session still won on UI/UX is something I need to figure out how to solve. But for now, that’s the story.